document types to superpositions
So, I was wondering if we could identify document types just by looking at frequency of bytes in that document. This post plans to test that idea.
First, some python:
import sys
from the_semantic_db_code import *
from the_semantic_db_functions import *
from the_semantic_db_processor import *
C = context_list("files to superpositions")
# empty superposition:
empty = show_range(ket("byte: 0"),ket("byte: 255"),ket("1")).multiply(0)
def file_to_sp(filename):
r = fast_superposition()
with open(filename,'rb') as f:
for line in f:
for c in line:
byte = str(c)
r += ket("byte: " + byte)
return (r.superposition().normalize(100) + empty).ket_sort()
files = [["binary","binary.exe"],["ebook","ebook.txt"],["encrypted","encrypted.gpg"],["website","website.html"],["zipped","zipped.zip"]]
for name, file in files:
print("name:",name)
result = file_to_sp("example-files/" + file)
C.learn("bytes",name,result)
for x in result: # spit out the results so we can graph them
print(x.value)
print("====================")
# save the results:
sw_file = "sw-examples/files-to-bytes.sw"
save_sw(C,sw_file)
Here is the resulting sw file.
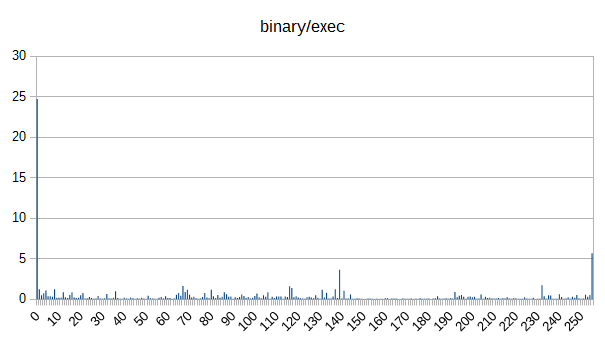
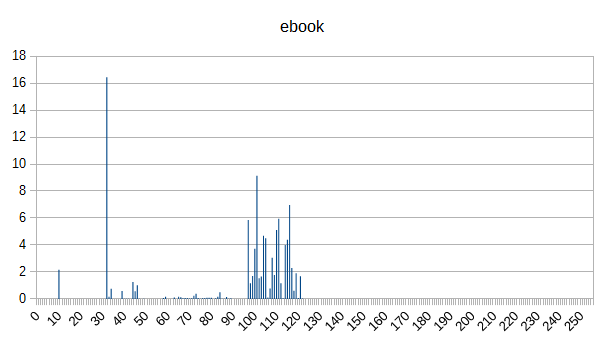
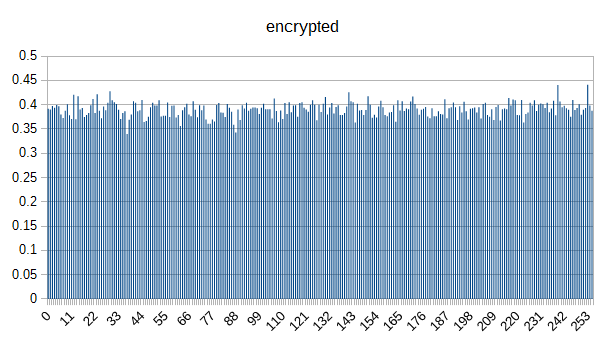
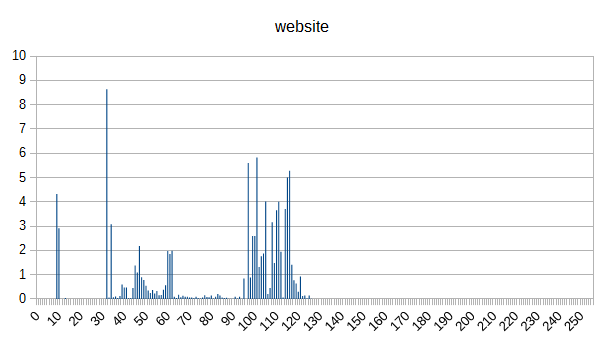
Here are the graphs:
Now, let's generate the similarity matrix:
sa: load files-to-bytes.sw
sa: simm |*> #=> 100 self-similar[bytes] |_self>
sa: map[simm,similarity] rel-kets[bytes] |>
sa: matrix[similarity]
[ binary ] = [ 100.0 12.44 47.86 16.07 47.64 ] [ binary ]
[ ebook ] [ 12.44 100.0 14.63 72.7 14.78 ] [ ebook ]
[ encrypted ] [ 47.86 14.63 100.0 21.97 97.6 ] [ encrypted ]
[ website ] [ 16.07 72.7 21.97 100.0 22.25 ] [ website ]
[ zipped ] [ 47.64 14.78 97.6 22.25 100.0 ] [ zipped ]
So yeah. You can largely differentiate between document types (at least for this small sample) based just on byte counts. Cool.
I guess that is it for this post. As usual, heaps more to come!
Update: I wonder how small a file can get and still have distinctive document type? Or even further, is it possible to write an "English-grep" that only prints out lines that look like English? Of course for that to work, you need more than just letter counts. You need to count letter pairs, and probably triples, or perhaps some other method of creating a line => superposition.
Home
previous: some wage prediction results
next: spike fourier transform using simm
updated: 19/12/2016
by Garry Morrison
email: garry -at- semantic-db.org